
Embeddings incontextuales: un algoritmo para representar palabras con números#
Hasta este momento, a la hora de representar palabras o frases hemos usado características (features) que nos han permitido trabajar de forma matemática con elementos lingüísticos. Estas características, sin embargo, son relativamente arbitrarias y exigen un esfuerzo por nuestra parte en su definición. Sin embargo, existe, como vamos a ver ahora, una manera más fundamentada para representar palabras con números que no requiere supervisión humana.
Nota
Esta página es parte de la serie "Un recorrido peso a peso por el transformer", donde se presenta una guía para aprender cómo funcionan las redes neuronales que procesan textos y cómo se programan. Es también posible que hayas llegado a ella desde otra fuente (por ejemplo, una asignatura específica) que plantee otra forma diferente de utilizar estos contenidos. En ese caso, usa las recomendaciones y la planificación que te ofrezca esa fuente.
Embeddings#
Los embeddings incontextuales se explican en el capítulo "Vector Semantics and Embeddings". Comienza leyendo la sección 6.2. Después, estudia la sección 6.4 sobre la similitud del coseno. Sáltate completamente las secciones 6.5 a 6.7. Céntrate, sobre todo, en la sección 6.8 ("Word2vec"), pero lee con menos detenimiento las secciones 6.9 a 6.12.
Anotaciones al libro#
Nota
Es recomendable que estudies estos comentarios después de una primera lectura del capítulo y antes de la segunda lectura.
Apartado 6.2
Los embeddings permiten representar palabras con números de forma que palabras que aparecen en contextos similares tengan representaciones similares. Esta representación numérica es esencial para poder hacer que las redes neuronales (u otros modelos de aprendizaje automático) puedan trabajar con el lenguaje humano. Si dada una frase podemos representar cada una de sus palabras mediante un vector, podemos entonces intentar aprender un clasificador que, por ejemplo, determine el sentimiento de la frase a partir de de la suma de los embeddings de sus palabras.
Aunque a lo largo de las últimas décadas se han desarrollado muchos métodos para obtener embeddings, algoritmos como el word2vec que estudiaremos en este capítulo fueron pioneros al permitir obtener representaciones profundas (en el sentido de que cada palabra se representa con un vector de cientos o miles de números reales), que mejoraron sustancialmente los resultados en numerosas tareas de procesamiento del lenguaje natural. Una característica de estos embeddings que hacen que no sean los más usados actualmente es que aprenden representaciones no contextuales, es decir, que una palabra como bajo con sus múltiples sentidos (búscala en el diccionario) se representa de la misma manera en todos los contextos. Como veremos más adelante, los embeddings contextuales como los obtenidos con los transformers ofrecen una representación única para cada palabra en cada oración en la que aparece.
La idea de por qué vectores de mayor tamaño permiten acercar y alejar de forma más adecuada las palabras en el espacio vectorial en base a su similitud se puede entender con el siguiente ejemplo. Supón que solo tuviéramos 2 dimensiones para representar palabras aparentemente con baja similitud como fish, Mars, pencil o hat. Si asumimos el cuadrado de lado 1.5 como espacio de trabajo, dado que estas palabras están poco relacionadas, tiene sentido llevarlas a las esquinas.
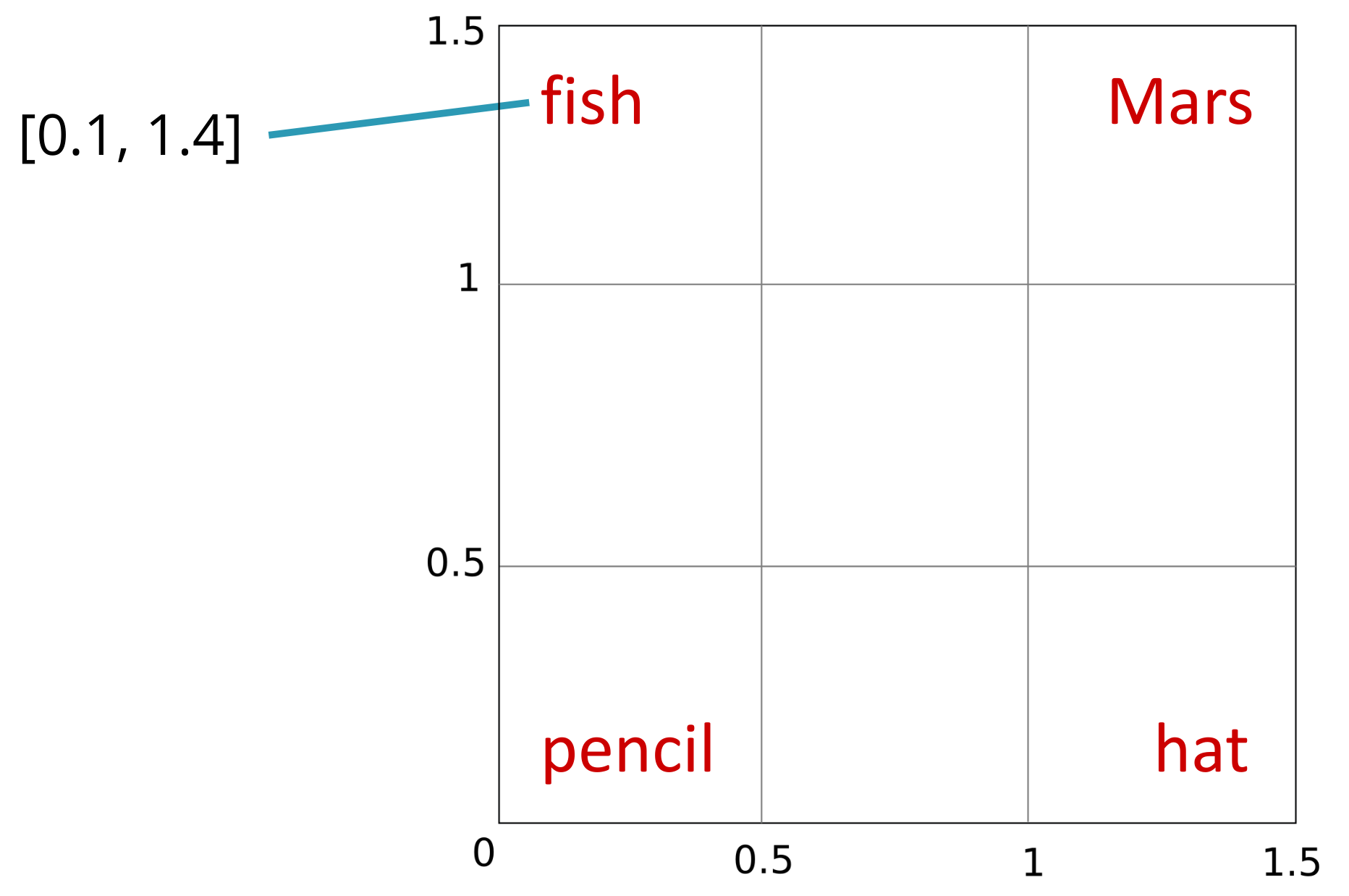
Si ahora quisiéramos encontrar una representación bidimensional para Sunday podríamos colocarla cerca de hat (a fin de cuentas, tradicionalmente la gente ha reservado para el domingo sus mejores sombreros), lo cual de paso aleja a Sunday de Mars o pencil con las que es más difícil que comparta contextos.
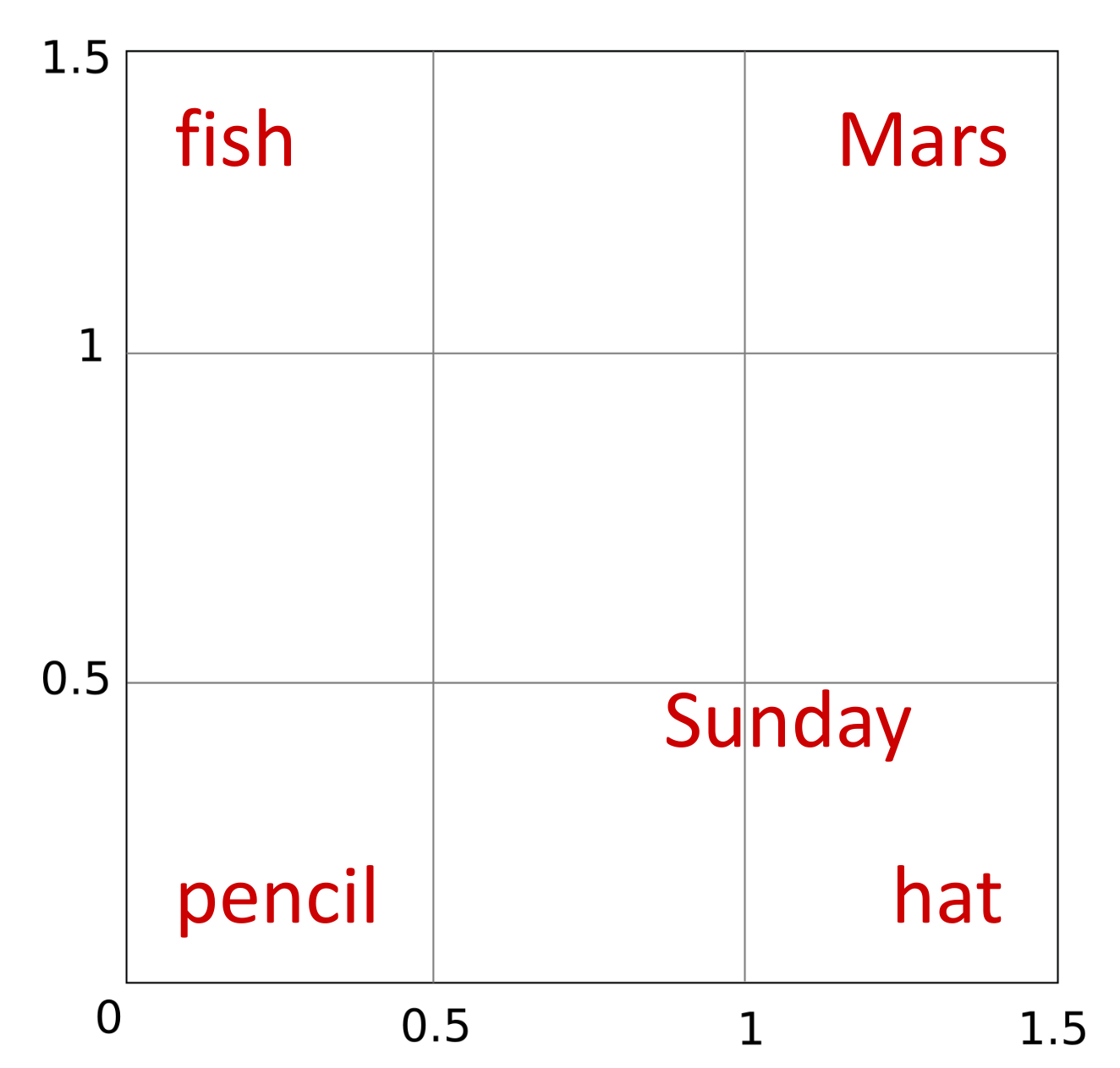
Ahora supongamos que queremos añadir a nuestra lista la palabra small. Dado que esta palabra puede acompañar a fish, hat o pencil y dado que Marte (si lo consideramos como un planeta, obviando que puede ser otras cosas como un dios, una marca de chocolatinas o parte del nombre de un famoso jardín parisino) es uno de los planetas más pequeños del sistema solar, podemos colocar small justo a mitad de camino de estas cuatro palabras. Sin embargo, esto también la acerca a Sunday con la que parece compartir pocos contextos.
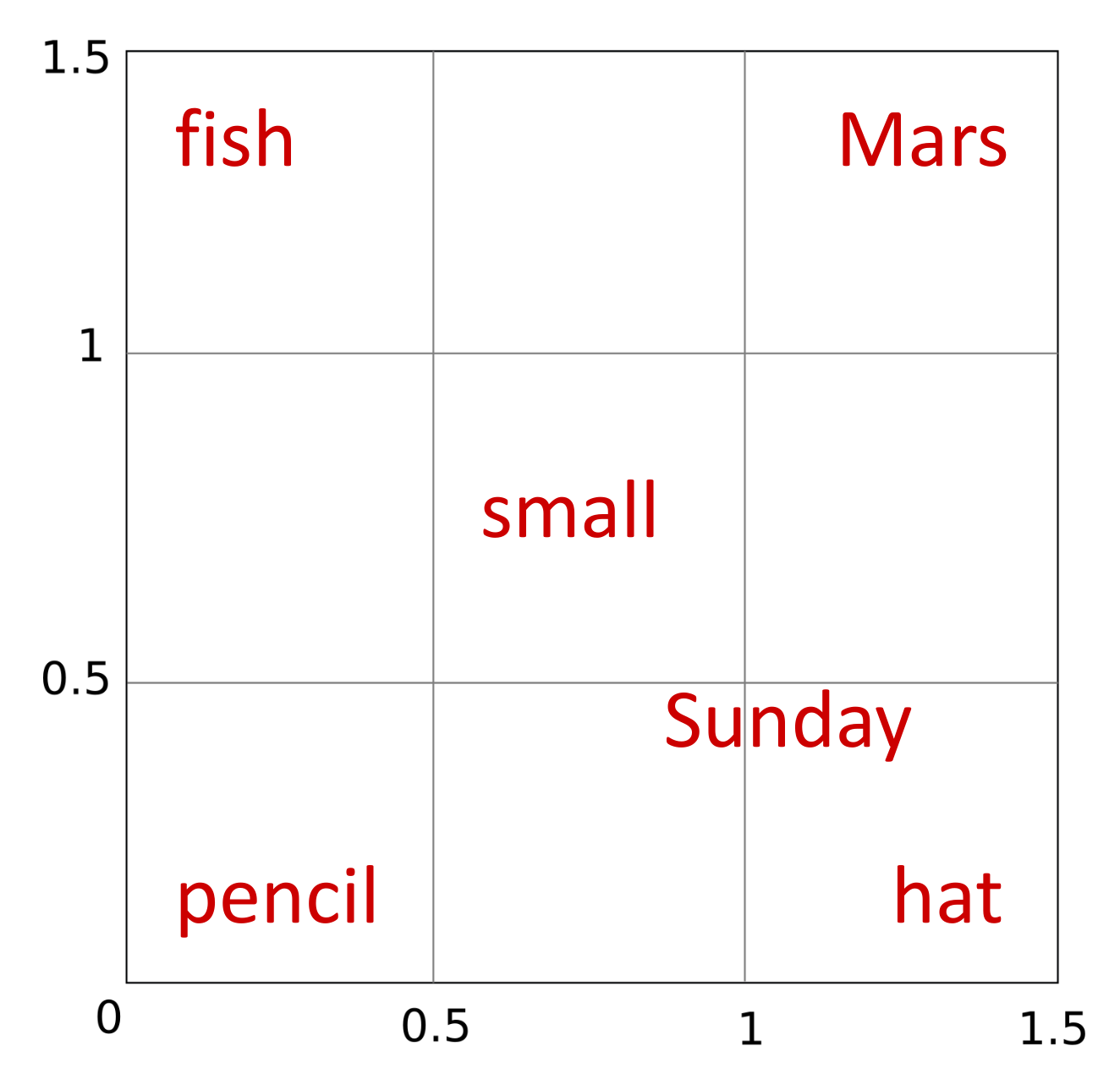
¿Te vas dando cuenta del problema? Es como si no hubiera espacio suficiente para cumplir con todas las restricciones. Una posible solución temporal es intercambiar Sunday y hat, pero podemos intuir que conforme vayamos añadiendo más palabras al pequeño espacio vectorial, el problema se irá haciendo más y más evidente.
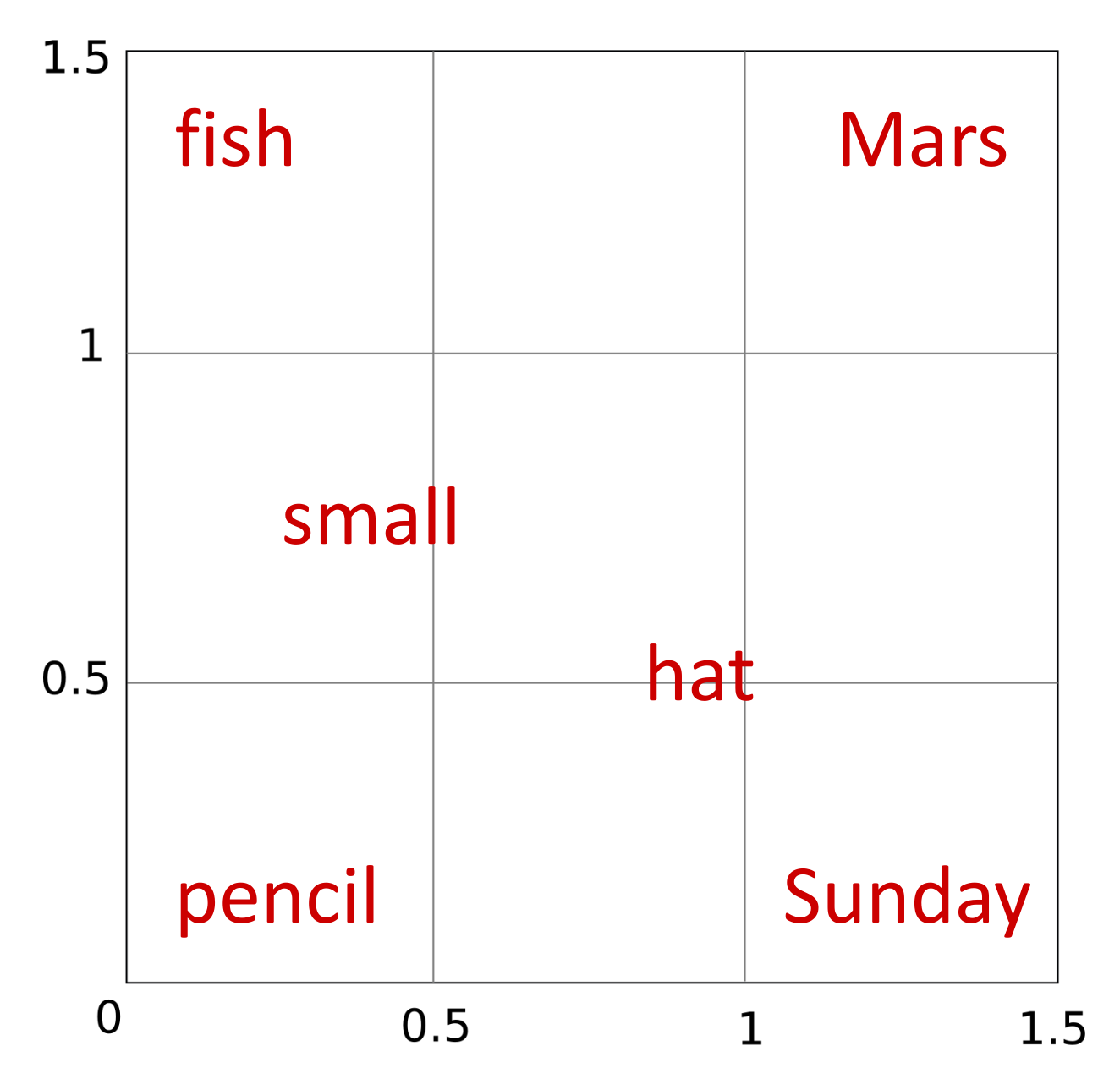
Si ahora quisiéramos añadir Phobos, evidentemente debería situarse cerca de Mars al ser un satélite de este planeta, pero eso la acercaría a palabras como hat y es difícil encontrar frases en las que se hable de lo usos del sombrero en el satélite Phobos. La clave está en poder añadir una tercera dimensión al espacio vectorial, lo cual nos permitiría separar Phobos del resto de palabras excepto Mars.
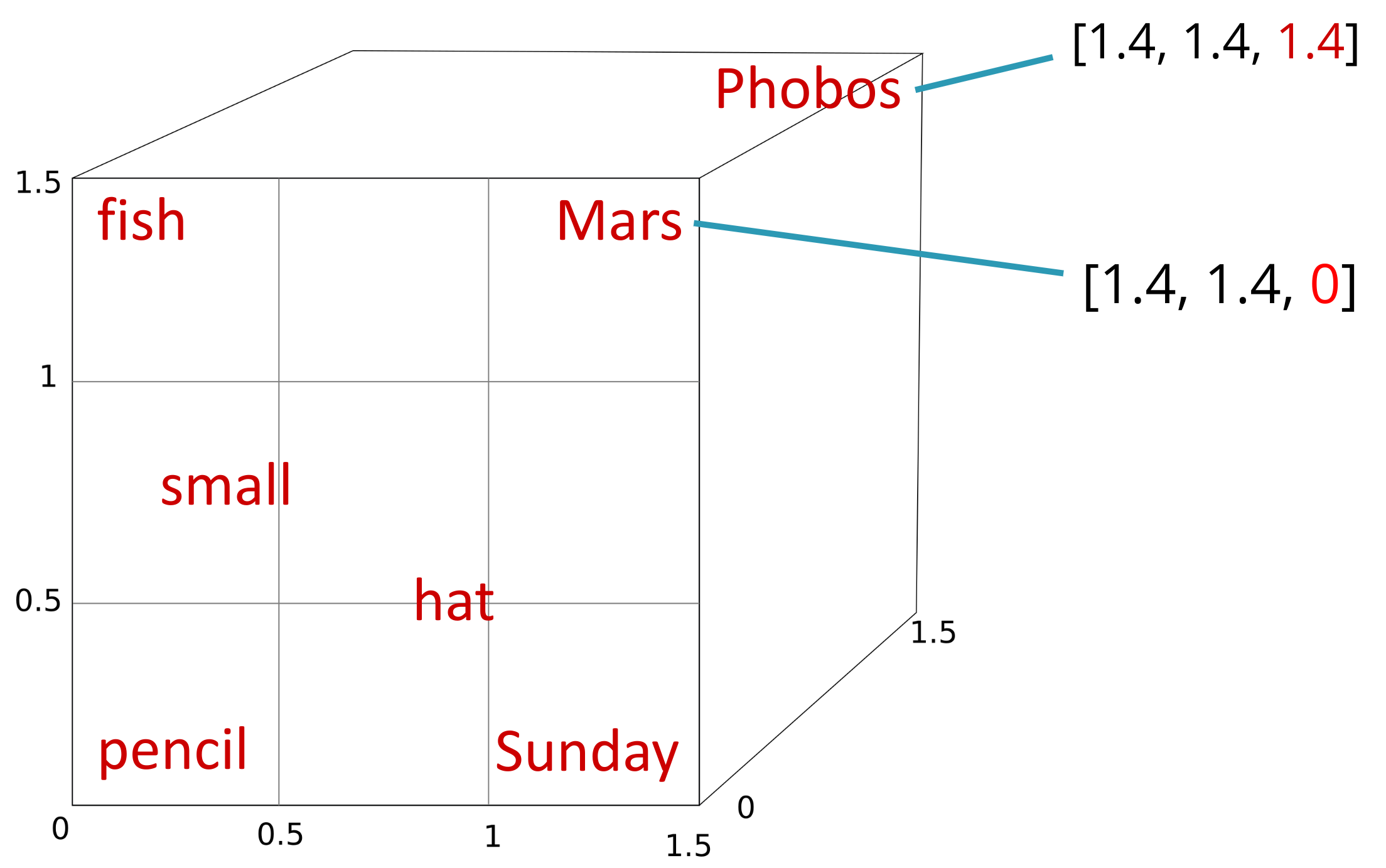
Es fácil deducir que aumentando el número de dimensiones del espacio vectorial, podemos representar las relaciones entre palabras con mayor precisión. Cuando pasemos a cientos o miles de dimensiones, algunas palabras estarán cerca de otras en algunos de las dimensiones, pero no en otras. Observa, en cualquier caso, que hay un problema que no vamos a resolver por ahora: que una palabra como Mars con varios sentidos diferentes tenga un único embedding. De hecho, podríamos decir que la mayoría de las palabras tienen sentidos diferentes en cada oración distinta en las que las utilicemos: la palabra gato en "El gato está dormido" y "El gato está asustado" no representa exactamente la misma idea de animal, pese a que discreticemos el concepto más profundo que tenemos en nuestra mente cuando queremos hablar del minino en una u otra situación. Este problema de no poder representar la semántica en un caso específico se resolverá más adelante con los embeddings contextuales.
Apartado 6.3
Esta sección es opcional, pero puedes echarle un vistazo si quieres conocer enfoques más clásicos para la obtención de embeddings basados en contar co-ocurrencias de palabras en documentos.
Apartado 6.4
Este es un apartado muy breve que, aun así, introduce una idea básica: la similitud del coseno (no lo llamamos distancia porque no cumple con todas las propiedades necesarias) entre dos vectores que representan los embeddings de dos palabras es una medida del parecido entre las palabras correspondientes. Si dos vectores son idénticos, su similitud es 1; si son ortogonales, su similitud es 0; si son opuestos, su similitud es -1.
Más aún, el producto escalar es proporcional a la similitud del coseno, pero implica menos cálculos, por lo que lo usaremos como una aproximación eficiente. Recordemos que el producto escalar de dos vectores \(\mathbf{a}\) y \(\mathbf{b}\) es:
Esta idea de sumar los productos dos a dos de los elementos de dos vectores aparece también en la multiplicación de matrices, por lo que podemos pensar en la multiplicación de dos matrices \(A \times B\) como la obtención de todos los posibles productos escalares entre las filas de \(A\) y las columnas de \(B\). Recuerda esta idea en el tema del transformer cuando usemos productos de matrices para compactar el cálculo de una serie de productos escalares y hacerlo todo de una vez.
Hay un párrafo en el que se menciona que al ser los valores de los vectores de embeddings positivos, el coseno estará siempre entre cero y uno. Ten en cuenta que esta afirmación es para el caso de embeddings obtenidos mediante procedimientos clásicos, que no hemos visto aquí, salvo por el ejemplo de la tabla de este apartado (en la que aparecen palabras como cherry o pie). En estos casos, los valores de los vectores son positivos porque resultan de contar frecuencias de co-ocurrencia de dos palabras en una colección de documentos. Sin embargo, en el caso de los embeddings de palabras que veremos a continuación, los valores de los vectores pueden ser negativos, por lo que el coseno puede ser menor que cero.
En cualquier caso, aunque el valor del coseno esté acotado entre -1 y 1, el del producto escalar no lo está.
Apartado 6.8
Este apartado introduce el algoritmo skip-gram para el cálculo de embeddings de palabras. Este algoritmo puede verse como una aplicación del regresor logístico binario que ya hemos estudiado, por lo que es recomendable que le des un repaso antes. Vamos a tener una serie de datos positivos (la salida deseada será 1) y una serie de datos negativos (la salida deseada será 0). Los datos positivos son pares de palabras que aparecen en el mismo contexto, mientras que los datos negativos son pares de palabras que no aparecen en el mismo contexto. El objetivo del algoritmo es aprender a predecir si dos palabras aparecen en el mismo contexto o no.
¿Pero si la salida del regresor es un único escalar entre 0 y 1, de dónde salen los embeddings? La idea es que cada palabra va a venir representada a la entrada por un vector diferente de pesos, de manera que la salida del regresor cuantificará cómo de probable es que dos palabras aparezcan en el mismo contexto. Y ya hemos visto que el producto escalar nos sirve para medir la similitud de dos vectores. Pero como este producto escalar no está acotado, le aplicamos la función sigmoide para normalizarlo en este rango.
La principal diferencia con el regresor logístico binario que ya vimos es que allí teníamos un vector de características \(\mathbf{x}\) que representaba la entrada y un vector de pesos \(\mathbf{w}\) que representaba los parámetros aprendibles por el algoritmo de descenso por gradiente. El vector de entrada venía determinado por los datos del problema y sus valores no se aprendían. En el caso de skip-gram, los dos vectores en juego son parámetros a aprender y estos vienen determinados por las dos palabras que queremos representar en cada momento. Una vez finalizado el entrenamiento, el vector de cada palabra será su vector de embeddings, que podremos usar para representarla en tareas adicionales. El sesgo \(b\) no se usa en este caso, ya que no es necesario.
Una de las grandes ventajas de este algoritmo es que se basa en una técnica de aprendizaje auto supervisada (self-supervised) que no requiere el costoso proceso de etiquetar manualmente los datos. No es que el algoritmo no necesite datos etiquetados, ya que necesita saber cuándo la salida deseada para dos palabras es 0 y cuándo es 1. Pero no necesita que estas etiquetas vengan ya dadas, sino que las puede obtener de forma automática a partir de los datos de entrada. Para ello solo necesitamos una colección de textos (por ejemplo, textos de la Wikipedia o noticias descargadas de internet) y definir una ventana de contexto. La ventana de contexto es un número entero que indica cuántas palabras a la izquierda y a la derecha de la palabra objetivo queremos considerar como contexto. El algoritmo extrae las muestras positivas recorriendo una a una las palabras del texto y considerando como contexto las palabras que hay a su izquierda y a su derecha dentro de la ventana. Las muestras negativas se obtienen de forma aleatoria, seleccionando dos palabras al azar del texto y considerando que no aparecen en el mismo contexto.
En el apartado 6.8.2 se dice que "the noise words are chosen according to their weighted unigram frequency \(p_α(w)\), where \(α\) is a weight". Ten en cuenta que la \(w\) se refiere aquí a una palabra que se va a elegir para una muestra negativa y no tiene que ver que con la palabra objetivo que se denota también con \(w\). Cuando dice que las palabras ruidosas se escogen en base a su probabilidad de unigramas, se refiere únicamente a que se escogen en base a su frecuencia de aparición en el texto: palabras más frecuentes se escogerán más veces que palabras menos frecuentes para no terminar aprendiendo representaciones de palabras que no aparecen apenas en el texto y de las que no vamos a tener apenas muestras positivas a costa de aprender peores representaciones de las palabras que más nos interesan. Observa también cómo el uso de una alteración no lineal en forma del exponente \(\alpha\) suaviza ligeramente estas frecuencias para no penalizar en exceso a las palabras poco frecuentes.
Las muestras negativas y positivas se combinan en un mini-batch y se entrenan usando una función de pérdida \(L_{\mathrm{CE}}\)como la de la ecuación (6.34), pero extendida a todo el lote incorporándole la media de los errores.
Finalmente, las ecuaciones (6.35) a (6.37) muestran las fórmulas del gradiente respecto a los parámetros del modelo. Estaría bien que te animaras a derivarlas por tu cuenta, pero no es estrictamente necesario para poder seguir el resto del curso. Si las comparas con detenimiento con las del regresor logístico binario que ya estudiamos, verás que, como no podía ser de otra manera, son iguales. Cuando la derivada es respecto a \(c_{\mathrm{pos}}\), por ejemplo, esta variable juega el papel de los pesos \(\mathbf{w}\) del regresor logístico y \(\mathbf{w}\) (el embedding de la palabra objetivo) se considera constante y juega el papel de la entrada \(\mathbf{x}\) en las derivadas del regresor logístico.
Apartados 6.9 a 6.12
Estos apartados son menos densos que el anterior y te ayudarán a entender otros aspectos derivados del uso de embeddings:
- la proyección de embeddings en espacios de dimensionalidad baja para su visualización;
- la aritmética de embeddings para extraer relaciones semánticas entre las palabras asociadas;
- la presencia y consecuencia de sesgos en los embeddings aprendidos;
- los conjuntos de datos de evaluación que permiten comparar distintas formas de obtener las representaciones de palabras.