


Next: Application of DTRNN to
Up: Discrete-time recurrent neural networks
Previous: Neural Moore machines
Contents
Index
Other architectures without hidden state
There are a number of discrete-time neural network
architectures
that do not have a
hidden state (their
state is observable because it is simply a combination of
past inputs and past outputs) but may still be classified as
recurrent. One such example is the NARX (Nonlinear Auto-Regressive
with eXogenous inputs) network used by
Narendra and Parthasarathy (1990) and then later by
Lin et al. (1996) and Siegelmann et al. (1996)
(see also (Haykin, 1998, 746)), which may be formulated in
state-space form by defining a state that is simply a window of the
last 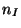 inputs and a window of the last
inputs and a window of the last 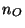 outputs. Accordingly, the next-state function simply incorporates a new input (discarding the oldest
one) and a freshly computed output (discarding the oldest one) to the
windows and shifts each one of them one position. The
outputs. Accordingly, the next-state function simply incorporates a new input (discarding the oldest
one) and a freshly computed output (discarding the oldest one) to the
windows and shifts each one of them one position. The
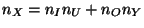 components of the state
vector are distributed as follows:
components of the state
vector are distributed as follows:
- The first
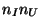 components are allocated to the window of the last
inputs:
components are allocated to the window of the last
inputs: ![$u_i[t-k]$](img184.png) (
(
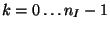 ) is stored in
) is stored in ![$x_{i+kn_U}[t]$](img186.png) ;
;
- The
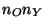 components from
components from 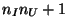 to
to 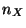 are allocated to
the window of the last outputs:
are allocated to
the window of the last outputs: ![$y_i[t-k]$](img189.png) (
(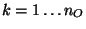 )
is stored in
)
is stored in
![$x_{n_In_U+i+(k-1)n_Y}[t]$](img191.png) .
.
The next-state function 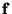 performs, therefore, the following operations:
performs, therefore, the following operations:
- Incorporating the new input and shifting past inputs
![\begin{displaymath}
\begin{array}{rlc}
f_i({\bf x}[t-1],{\bf u}[t]) =& u_i[t], &...
...]) =& x_{i-{n_U}}[t-1], & {n_U} <i\le {n_U} n_I
\\
\end{array}\end{displaymath}](img193.png) |
(4.16) |
- Shifting past outputs:
![\begin{displaymath}
f_i({\bf x}[t-1],{\bf u}[t]) = x_{i-{n_Y}}[t-1],\;\; {n_U}n_I+{n_Y} <
i\le {n_X};
\end{displaymath}](img194.png) |
(4.17) |
- Computing new state components using an intermediate hidden
layer of
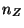 units:
units:
![\begin{displaymath}
f_{i+{n_U}n_i}({\bf x}[t-1],{\bf u}[t]) =
g\left(\sum_{j=1}^{n_Z} W_{ij}^{xz} z_j[t] + W_i^x \right),\; 1
\le i \le n_Y
\end{displaymath}](img196.png) |
(4.18) |
with
![\begin{displaymath}
z_i[t] = g\left(\sum_{j=n_U+1}^{n_X} W_{ij}^{zx} x_i[t-1] +
...
...^{n_U} W_{ij}^{zu} u_j[t] + W_i^z \right),\;
1 \le i \le n_Z.
\end{displaymath}](img197.png) |
(4.19) |
The output function is then simply
![\begin{displaymath}
h_i({\bf x[t]}) = x_{i+{n_U}n_I}[t],
\end{displaymath}](img198.png) |
(4.20) |
with
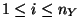 . Note that the output is computed by a
two-layer feedforward neural network. The
operation of a NARX network
. Note that the output is computed by a
two-layer feedforward neural network. The
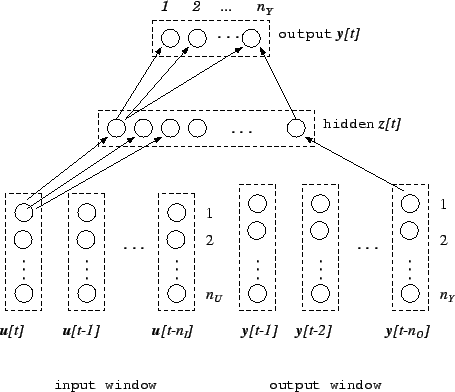
operation of a NARX network 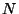 may then be summarized as follows (see figure 3.3):
may then be summarized as follows (see figure 3.3):
![\begin{displaymath}
{\bf y}[t]=N({\bf u}[t],{\bf u}[t-1],\ldots,{\bf u}[t-n_I],{\bf y}[t-1],{\bf y}[t-2],\ldots,{\bf y}[t-n_O]).
\end{displaymath}](img200.png) |
(4.21) |
Their operation is therefore a nonlinear variation of that of an ARMA
(Auto-Regressive, Moving Average) model or that of an IIR ( Infinite-time Impulse Response) filter.
Figure 3.3:
Block diagram of a NARX network (the network is fully
connected but all arrows have not been drawn for clarity).
|
|
When the state of the discrete-time neural network is simply a window of
past inputs, we have a network usually called a time delay neural
network (TDNN) (see also
(Haykin, 1998, 641)). In state-space formulation, the
state is simply the window of past inputs and the next-state
function
simply incorporates a new input to the window and shifts it one
position in time:
![\begin{displaymath}
\begin{array}{rlc} f_i({\bf x}[t-1],{\bf u}[t]) =& x_{i-{n_U...
...f x}[t-1],{\bf u}[t]) =& u_i[t],&
1\le i\le {n_U},
\end{array}\end{displaymath}](img202.png) |
(4.22) |
with
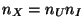 ; and the
output is usually computed by a two-layer perceptron (feedforward
net):
; and the
output is usually computed by a two-layer perceptron (feedforward
net):
![\begin{displaymath}
h_{i}({\bf x}[t-1],{\bf u}[t]) =
g\left(\sum_{j=1}^{n_Z} W_{ij}^{yz} z_j[t] + W_i^y \right),\; 1
\le i \le n_Y
\end{displaymath}](img204.png) |
(4.23) |
with
![\begin{displaymath}
z_i[t] = g\left(\sum_{j=1}^{n_X} W_{ij}^{zx} x_i[t-1] +
\su...
...^{n_U} W_{ij}^{zu} u_j[t] + W_i^z \right),\;
1 \le i \le n_Z.
\end{displaymath}](img205.png) |
(4.24) |
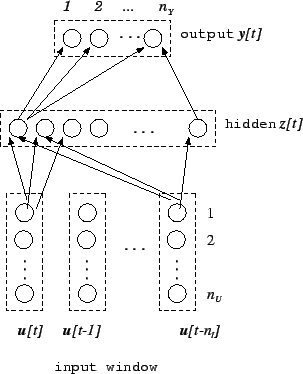
The operation of a TDNN network may then be summarized as follows
(see figure 3.4):
![\begin{displaymath}
{\bf y}[t]=N({\bf u}[t],{\bf u}[t-1],\ldots,{\bf u}[t-n_I]).
\end{displaymath}](img206.png) |
(4.25) |
Their operation is therefore a nonlinear variation of that of an MA
(Moving Average) model or that of a FIR (Finite-time Impulse
Response) filter.
Figure 3.4:
Block diagram of a TDNN (the network is fully
connected but all arrows have not been drawn for clarity).
|
|
The weights
connecting the window of inputs to the hidden layer may be organized in
blocks sharing weight
values, so that the components of the hidden layer retain some of the temporal ordering in
the input window. TDNN have been used for tasks
such as phonetic transcription
(Sejnowski and Rosenberg, 1987), protein secondary
structure prediction (Qian and Sejnowski, 1988), or phoneme recognition
(Waibel et al., 1989; Lang et al., 1990). Clouse et al. (1997b) have studied the ability
of TDNN to represent and learn a class of finite-state
recognizers from examples (see also
(Clouse et al., 1997a) and (Clouse et al., 1994))4.8.
Next: Application of DTRNN to
Up: Discrete-time recurrent neural networks
Previous: Neural Moore machines
Contents
Index
Debian User
2002-01-21