



Next: #manolios94j###
Up: Inference of finite-state machines
Previous: #pollack91j###:
Contents
Index
The architecture used by these authors is very similar to that used by
Pollack (1991): a second-order DTRNN (see section 3.2.1)
which is trained using
the RTRL algorithm (Williams and Zipser, 1989c) (see
section 3.4.1). The
presentation scheme is one of the main innovations in this paper:
training starts with a small random subset; if the DTRNN either learns
to classify it perfectly or spends a maximum number of training
epochs, the learning set is incremented with a
small number of randomly chosen strings. When the network correctly
classifies the whole learning set, then it is said to converge. A
special symbol is used to signal the end of
strings; this gives the network extra
flexibility, and may be easily shown to be equivalent to adding a
single-layer feedforward neural network as an output layer, as done by
Blair and Pollack (1997) or Carrasco et al. (1996)(see
section 3.2.2). These authors extract automata from DTRNN by
dividing the state space hypercube in 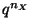 equally-sized
regions. The extraction algorithm has been explained in
more detail in section 5.4. One of the main results is
that, in many cases, the deterministic finite
automata
extracted from the dynamics of the DTRNN
exhibit better generalization than the DTRNN
itself. This is related to the fact that the DTRNN may not be behaving
as the corresponding FSM in the sense
discussed in section 4.2, but instead it shows what some
authors call unstable behavior (see section 5.3.2).
equally-sized
regions. The extraction algorithm has been explained in
more detail in section 5.4. One of the main results is
that, in many cases, the deterministic finite
automata
extracted from the dynamics of the DTRNN
exhibit better generalization than the DTRNN
itself. This is related to the fact that the DTRNN may not be behaving
as the corresponding FSM in the sense
discussed in section 4.2, but instead it shows what some
authors call unstable behavior (see section 5.3.2).
Next: #manolios94j###
Up: Inference of finite-state machines
Previous: #pollack91j###:
Contents
Index
Debian User
2002-01-21