



Next: State-based sequence processors
Up: Sequence processing with neural
Previous: Sequence processing with neural
Contents
Index
Processing sequences
The word sequence (from Latin sequentia, i.e., ``the
ones following'') is used to refer to a series of data items, each one
taken from a certain set of possible values  , so that each one of
them is assigned an index (usually consecutive integers) indicating
the order in which the data items are generated or
measured.4.1 Since the index usually refers to time, some
researchers like to call sequences time series as in ``time
series prediction''
(Box et al., 1994; Weigend and Gershenfeld, 1993; Janacek and Swift, 1993). In
the field of signal processing, this would
usually be called a discrete-time sampled
signal;
researchers in this field would identify the subject of this
discussion as that of discrete-time signal processing
(Ifeachor and Jervis, 1994; Oppenheim and Schafer, 1989; Mitra and Kaiser, 1993).
, so that each one of
them is assigned an index (usually consecutive integers) indicating
the order in which the data items are generated or
measured.4.1 Since the index usually refers to time, some
researchers like to call sequences time series as in ``time
series prediction''
(Box et al., 1994; Weigend and Gershenfeld, 1993; Janacek and Swift, 1993). In
the field of signal processing, this would
usually be called a discrete-time sampled
signal;
researchers in this field would identify the subject of this
discussion as that of discrete-time signal processing
(Ifeachor and Jervis, 1994; Oppenheim and Schafer, 1989; Mitra and Kaiser, 1993).
In
most of the following, it will be considered, for convenience, that is a
vector space in the broadest possible sense.
Examples of sequences would be:
- strings (words) on an alphabet (where would be the
alphabet of possible letters and the integer labels
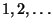 would be used to refer to the
first, second, etc. symbol of the string)
would be used to refer to the
first, second, etc. symbol of the string)
- acoustic vectors obtained every
 milliseconds after suitable
preprocessing of a speech signal (here would be a
vector space and the indices would refer to sampling times)
milliseconds after suitable
preprocessing of a speech signal (here would be a
vector space and the indices would refer to sampling times)
What can be done with sequences? Far from having the intention of being
exhaustive and formal, one may classify sequence
processing
operations in the following broad classes:4.2
- Sequence classification, sequence
recognition:
- in this kind of processing, a whole sequence
![$u=u[1]u[2]\ldots u[L_u]$](img98.png) is read and a single value, label or
pattern (not a sequence)
is read and a single value, label or
pattern (not a sequence) 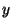 , taken from a suitable set
, taken from a suitable set 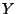 , is
computed from it. For example, a sequence of acoustic vectors such
as the one mentioned above may be assigned a label that describes
the word that was pronounced, or a vector of probabilities for each
possible word. Or a string on a given alphabet may be recognized as
belonging to a certain formal language. For convenience, will
also be considered to be some kind of vector
space.
, is
computed from it. For example, a sequence of acoustic vectors such
as the one mentioned above may be assigned a label that describes
the word that was pronounced, or a vector of probabilities for each
possible word. Or a string on a given alphabet may be recognized as
belonging to a certain formal language. For convenience, will
also be considered to be some kind of vector
space.
- Sequence transduction or translation, signal
filtering:
- In this kind of processing, a sequence
is transformed into another sequence
![$y=y[1]y[2]\ldots y[L_y]$](img100.png) of data items taken from a set . In
principle, the lengths of the input
of data items taken from a set . In
principle, the lengths of the input 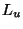 and the output
and the output 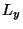 may be different. Processing may occur in
different modes: some sequence processors read the whole input
sequence
may be different. Processing may occur in
different modes: some sequence processors read the whole input
sequence 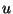 and then generate the sequence . Another mode is
sequential
processing, in which the
output sequence is
produced incrementally while processing the input
sequence. Sequential processing has the interesting
property that, if the result of processing of a given sequence
and then generate the sequence . Another mode is
sequential
processing, in which the
output sequence is
produced incrementally while processing the input
sequence. Sequential processing has the interesting
property that, if the result of processing of a given sequence 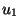 is a sequence
is a sequence 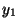 , then the result of processing a sequence that
starts with is always a sequence that starts with (this
is sometimes called the prefix property). A special case of
sequential processing is synchronous
processing: the processor
reads and writes one data item at a time, and therefore, both
sequences grow at the same rate during processing. For example,
Mealy and Moore machines, defined in section 2.3, are sequential,
finite-memory, synchronous processors that read and write symbol
strings. Examples of transductions and
filtering include machine translation of sentences and filtering of
a discrete-time sampled
signal.
Note that sequence classification applied to each prefix
, then the result of processing a sequence that
starts with is always a sequence that starts with (this
is sometimes called the prefix property). A special case of
sequential processing is synchronous
processing: the processor
reads and writes one data item at a time, and therefore, both
sequences grow at the same rate during processing. For example,
Mealy and Moore machines, defined in section 2.3, are sequential,
finite-memory, synchronous processors that read and write symbol
strings. Examples of transductions and
filtering include machine translation of sentences and filtering of
a discrete-time sampled
signal.
Note that sequence classification applied to each prefix ![$u[1]$](img105.png) ,
,
![$u[1]u[2]$](img106.png) , etc. of a sequence
, etc. of a sequence
![$u[1]u[2]u[3]\ldots$](img107.png) is equivalent to
synchronous sequence
transduction.
is equivalent to
synchronous sequence
transduction.
- Sequence continuation or prediction:
-
In this case, the sequence processor reads a sequence
![$u[1]u[2]\ldots u[t]$](img108.png) and produces as an
output a possible
continuation of the sequence
and produces as an
output a possible
continuation of the sequence
![$\hat{u}[t+1]\hat{u}[t+2]...$](img109.png) . This is
usually called time series
prediction and has interesting applications in meteorology or
finance, where the ability to predict the future behavior of a
system is a primary goal. Another interesting application of
sequence prediction is predictive coding
and compression. If the prediction is good
enough, the difference between the predicted continuation of the
signal and its actual continuation may be transmitted using a
channel with a lower bandwidth or a lower bit rate. This is
extensively used in speech
coding
(Sluijter et al., 1995), for example, in digital cellular phone systems.
. This is
usually called time series
prediction and has interesting applications in meteorology or
finance, where the ability to predict the future behavior of a
system is a primary goal. Another interesting application of
sequence prediction is predictive coding
and compression. If the prediction is good
enough, the difference between the predicted continuation of the
signal and its actual continuation may be transmitted using a
channel with a lower bandwidth or a lower bit rate. This is
extensively used in speech
coding
(Sluijter et al., 1995), for example, in digital cellular phone systems.
- Sequence generation:
- in this mode, the process generates an output
sequence
![$y[1]y[2]\ldots$](img110.png) from a single input or no input at all. For
example, a phone number inquiry
system may generate a synthetical pronunciation of each digit.
from a single input or no input at all. For
example, a phone number inquiry
system may generate a synthetical pronunciation of each digit.
Subsections
Next: State-based sequence processors
Up: Sequence processing with neural
Previous: Sequence processing with neural
Contents
Index
Debian User
2002-01-21